用 Hermes Agent + NotebookLM 跑完《罪与罚》之后,我发现自动化读书最难的不是“总结”。
项目仓库:https://github.com/xdlkc/notebooklm-workflow

我最近想认真读一遍《罪与罚》。
不是那种“给我三分钟讲完”的读法,而是想把它当成一次完整读书项目:人物关系要理清,拉斯柯尔尼科夫的心理变化要看见,索尼娅、波尔菲里、斯维德里盖洛夫这些人物各自承担什么作用,也要能讲出来。
最好读完之后,还能顺手变成一套材料:读书会问题、PPT、信息图、视频概览、音频概览。以后写文章、做分享、录播客,都不用从零开始。
结果书还没真正读起来,我先被一堆杂活卡住了。
文件从哪里来?EPUB 能不能直接用?要不要转 PDF?上传 NotebookLM 之后 source 什么时候 ready?如果要做 PPT,是直接让 NotebookLM 生成,还是先整理人物、主题和问题?生成完的信息图到底能不能发?视频要不要检查时长?最后这些文件放哪里?
这些事单独看都很小。
但它们连起来,就不是“读书”了,而是一条小型生产线。
于是我开始想:我真正需要的不是 AI 替我读书,而是一个能在旁边跑腿、整理、追问、检查、归档的助手。
我后来叫它“AI 书童”。
NotebookLM 很强,但它只管中间一段
一开始我以为 NotebookLM 已经够用了。
它可以上传资料,可以问答,可以生成 Studio 产物。看起来只要把书丢进去,再点几下,就能拿到 PPT、音频、视频和信息图。
但跑起来之后,我发现它只解决了中间一段。
它不会帮我准备 source,不会帮我判断 EPUB 还是 PDF 更稳定,不会提醒我 source 还没 ready 就别急着生成,也不会在产物生成后自动帮我下载、检查、归档。
更要命的是,它说“生成完成”,不代表这个东西真的能交付。
PPT 可能页数不够,信息图可能中文错字,视频可能还没完全下载,artifact list 可能间歇性 timeout。屏幕上出现 completed 的那一刻,工作其实只完成了一半。
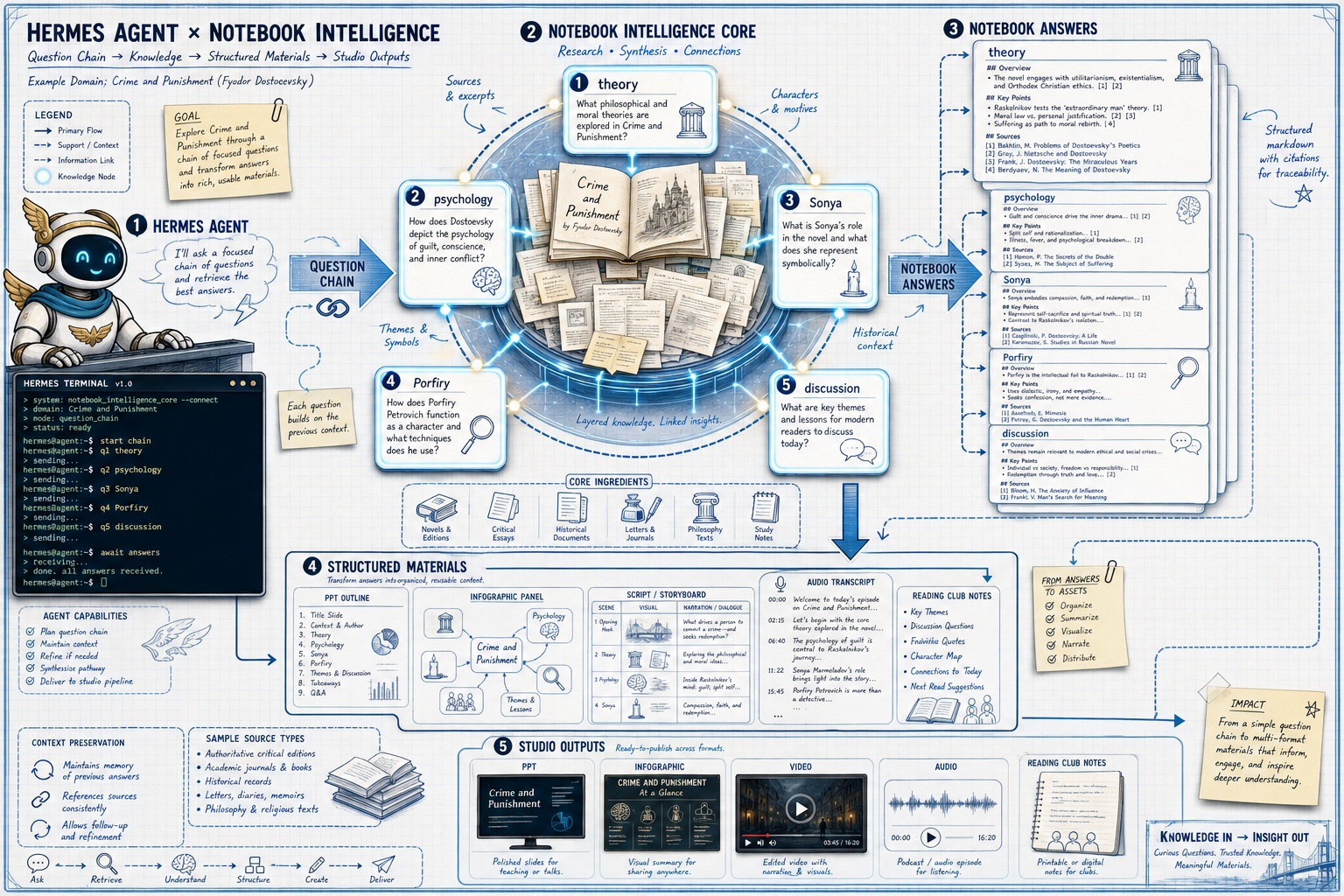
所以我最后把 NotebookLM 放在 workflow 的中间:它负责理解书和生成表达形式,但前后的脏活要交给 Agent 和 skills。
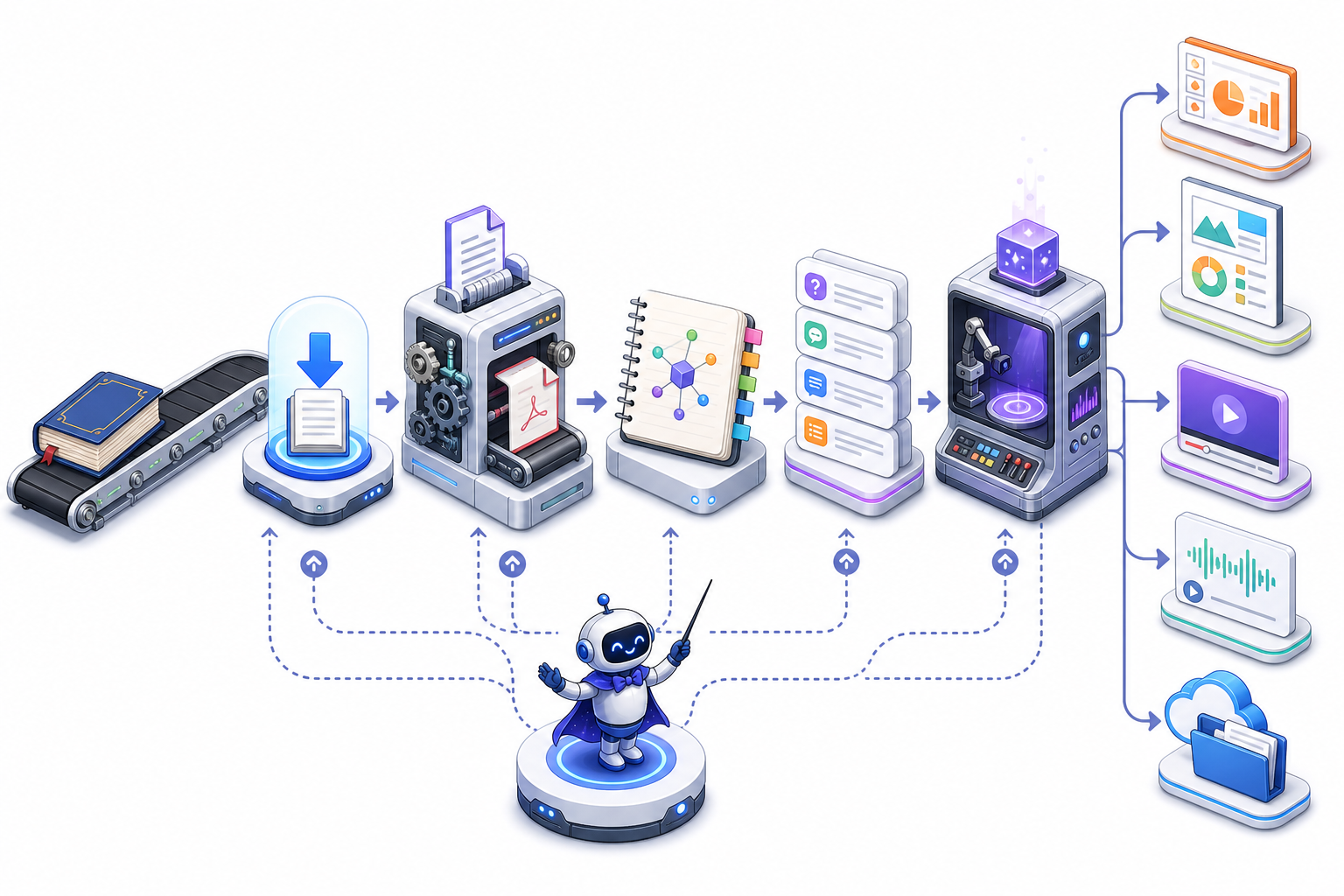

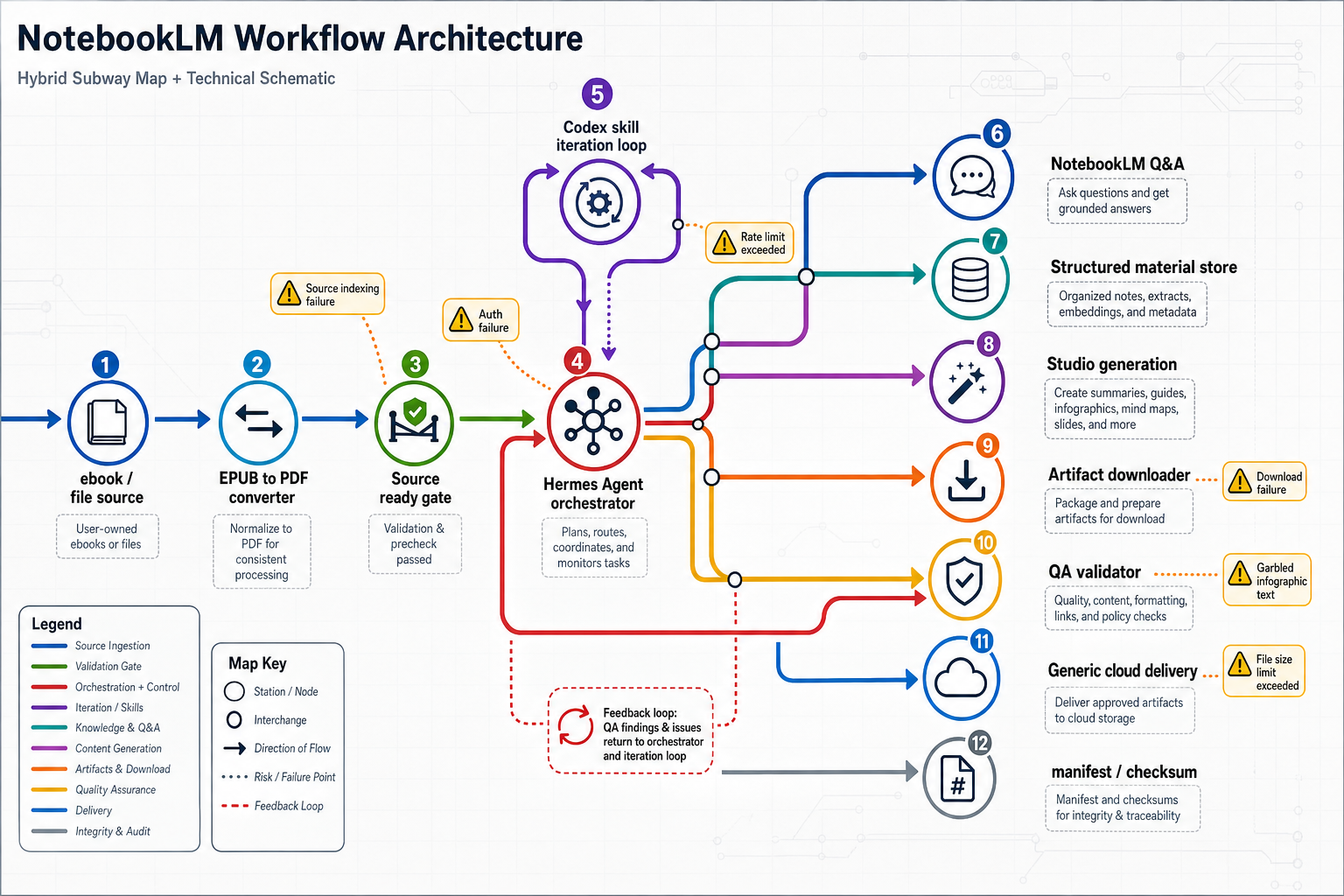
这条链路最后长这样:
一本书 |
这不是“上传一本书,然后让 NotebookLM 随便生成 PPT”。
这里真正有价值的是:每一步都有状态,每个产物都有检查,每次翻车都能写回流程。
这个“书童”其实是几个东西拼起来的

这套东西不是一个单独的应用。
Hermes Agent 负责调度。它像管家,知道什么时候该调用 skill,什么时候要等,什么时候要重试,什么时候不能直接把结果交出去。
Codex 负责帮我写和改 skills。很多步骤一开始只是临时命令,跑着跑着就发现:这事下次一定还会遇到,应该固化下来。
NotebookLM 负责理解 source、回答问题、生成 Studio 产物。
CLI / Skills 负责具体动作:转 PDF、上传 source、等待 ready、生成产物、下载文件、检查 PPT、检查视频、上传 Google Drive、生成 checksum 和 manifest。
我一开始以为 skills 就是“命令说明书”。
跑完这次之后,我发现它更像经验库。
比如:非交互环境下某些下载方式会失败;ebook-convert 不一定在 PATH;NotebookLM 上传 PDF 可能 timeout;artifact list 也会 timeout;Studio 产物生成成功不代表质量通过;中文信息图不能给太长文案;Drive 交付前要确认文件完整。
这些如果只靠人记,下次还会踩。
写进 skill 之后,它就变成 workflow 的一部分。
自动化不是没有坑,而是把坑写进 skill,下次少踩。
为什么我拿《罪与罚》做测试
我没有选一本商业书,也没有选技术手册。
不是因为它们不重要,而是它们太适合被整理了。很多商业书天然就是“几个原则、几个步骤、几个案例”。让 AI 拆这种书,很容易看起来效果不错。
我想试一个更麻烦的文本。
《罪与罚》有故事、有心理、有伦理冲突,有人物之间复杂的镜像关系。拉斯柯尔尼科夫不是一个“主角卡片”就能解释完的人,索尼娅也不是简单的“善良女性”,波尔菲里的审讯也不只是侦探桥段。
如果这个 workflow 只能处理“十个原则、五个方法”的书,那它只是一个总结器。
我想知道它能不能处理一本文学作品:能不能拆人物关系,能不能追踪心理崩塌,能不能把“惩罚不只是法律惩罚”这种主题变成可讨论、可展示、可复用的材料。
所以我用《罪与罚》跑了一遍完整流程。
真实 demo 放在:
demos/zuiyufa |
里面不只是最终文件,还保留了 prompts、logs、metadata、review outputs、ppt previews。这个目录本身就是文章素材库。
跑完之后,不只是一份摘要
这次跑通后,我拿到的东西大概分三类。
第一类是理解材料。
比如人物关系、章节结构、主题拆解、关键情节、道德困境、读书会讨论问题。这些材料不是最终成品,但它们很重要,因为后面的 PPT、信息图、视频、文章都从这里长出来。
第二类是展示材料。
PPT、信息图、视频概览、音频 / 播客式概览,都属于这一类。
这次实际产物里,PDF source 是 424 页;PPT 是 20 slides;PPT PDF 是 20 pages;最终信息图是 1536 x 2752 PNG;视频概览是 1280x720,约 414.9 秒。
我不想只在文章里写“生成了 PPT”。那样太像验收报告。
更好的方式是直接把 NotebookLM 的产物摆出来。
PPT 的 20 页预览长这样:

这套 PPT 不是普通摘要,它被要求做成“中文详细版 PPT”,既能做读书分享,也能展示 workflow 怎么把一本小说变成知识作品。里面有封面、故事核心问题、人物关系图、六部结构、犯罪理论、波尔菲里的心理追问、索尼娅的苦难陪伴、城市空间与贫困压迫,也有 workflow 复用价值和最后的可验证链路。
我挑几页单独放出来会更直观。
封面页是这个项目的核心隐喻:一本小说如何变成一套可分享知识作品。

人物关系页把拉斯柯尔尼科夫、索尼娅、杜尼娅、拉祖米欣、波尔菲里、斯维德里盖洛夫放到同一张图里。对小说来说,这比一段摘要有用得多。
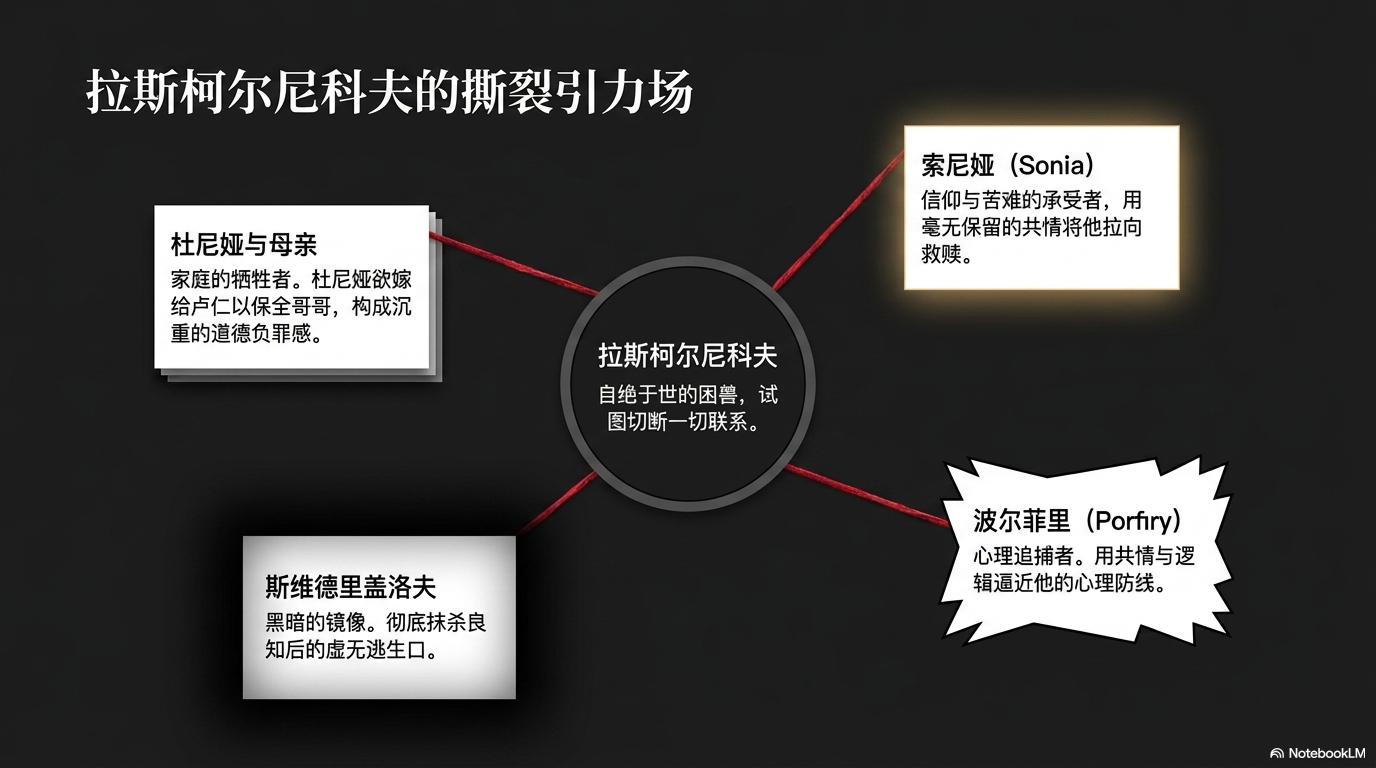
中间的主题页会继续展开犯罪理论、心理崩塌、审讯、忏悔和救赎。它不是“读后感”,更像把小说拆成一组可以讲的模块。
视频概览也不是一句“生成了视频”就完事。它的 prompt 要求按 7 个分镜组织:Hook、Source、Ready Gate、Novel Core、Artifact Matrix、QA、Delivery。既然这里讲的是 NotebookLM 真实产物,就应该直接把视频放出来,而不是只放截图。
信息图是另一种表达形式。它适合快速复盘,不适合承载太多解释,所以最终版本被我压缩成更稳定的短文案和固定模块。
这些真实产物都在 demo 目录里:
demos/zuiyufa/ppt_previews/ppt_contact_sheet.html |
第三类是交付记录。
Drive 目录、manifest、checksum、validation summary。
这些东西看起来不像“内容”,但我现在觉得它们非常重要。因为它们回答的是另一类问题:这个产物从哪里来?有没有检查过?文件有没有变?下次怎么复现?哪里曾经失败过?
Google Drive 交付目录在这里:
NotebookLM/《罪与罚》NotebookLM Workflow 实测 Demo |
validation summary 里留下了这次实测的关键信息:source ready、PPT 通过、信息图最终版通过、视频通过,以及几个具体卡点。
这就不是一次“生成几个文件”的演示了。
它更像一次有证据链的读书素材生产。
我最在意的,其实是那串问题


这次真正让我改观的,不是 NotebookLM Studio 能生成 PPT 或视频。
这些功能当然有用,但不是最核心的部分。
最核心的是:你到底怎么问这本书。
如果我直接写:
请基于《罪与罚》生成一套 PPT。 |
NotebookLM 大概率也能生成一套看起来还不错的东西。但它怎么取舍,哪些人物被强调,哪些主题被放大,哪些细节被省掉,我很难控制。
所以我更愿意先做结构化问答。
围绕《罪与罚》,可以问:
拉斯柯尔尼科夫的犯罪理论是什么?
他的心理崩塌是如何发生的?
索尼娅在故事里承担什么作用?
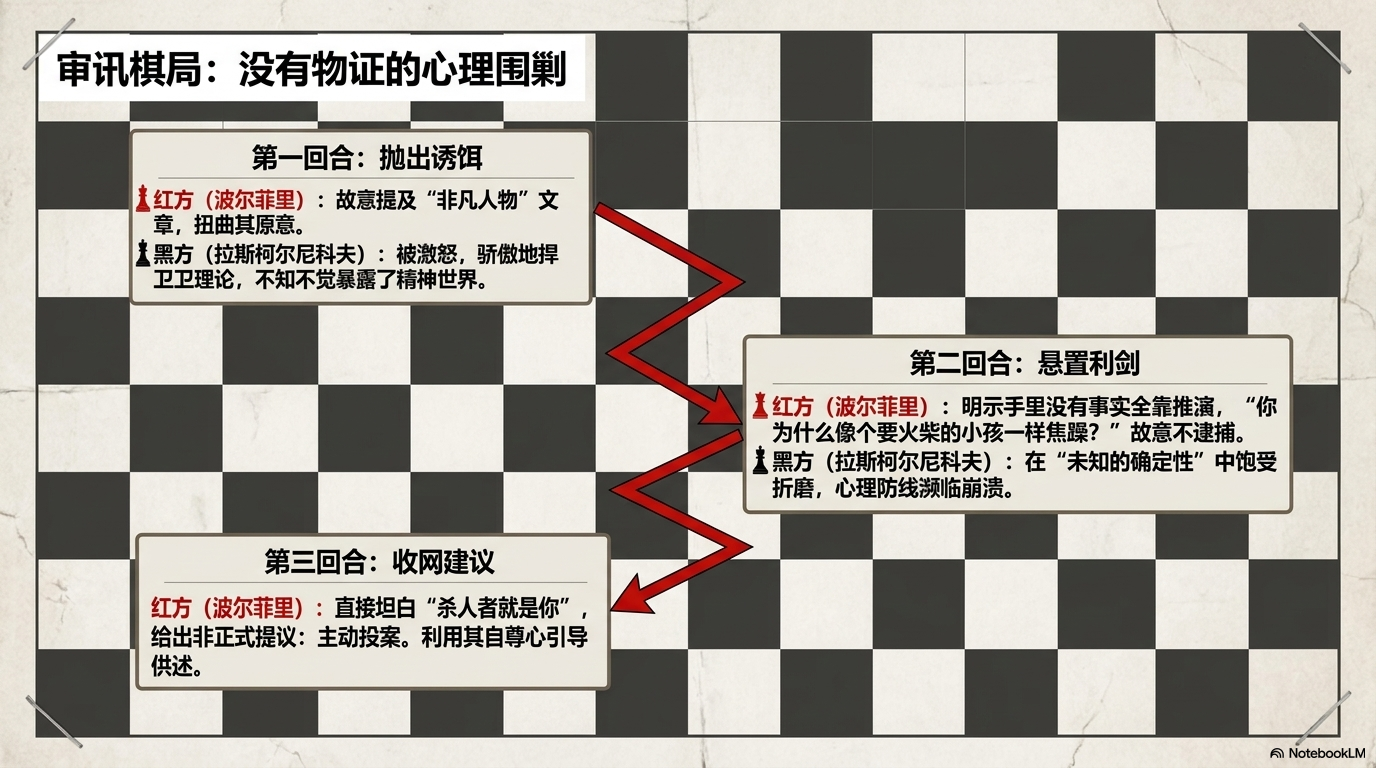
波尔菲里的审讯为什么重要?
“惩罚”为什么不只是法律惩罚?
哪些人物关系适合画成图?
哪些主题适合做成 PPT?
哪些问题适合读书会讨论?
这些问题不是为了得到几个答案,而是在把书拆成后续可组织的材料。
人物关系可以进 PPT。
心理变化可以做时间线。
道德困境可以做读书会讨论。
关键场景可以做视频分镜。
主题对照可以做信息图。
所以我现在更愿意把 NotebookLM Studio 看成最后一层表达,而不是起点。
起点是问题链条。
我后来又专门把这组问答补了一遍,放到:
demos/zuiyufa/notebooklm_answers/ |
下面贴几段真实的 NotebookLM 问答片段。这里有意思的地方是,它们不是最终产物,但它们会变成最终产物的“中间层素材”。PPT 里的理论页、人物关系页、信息图里的三个角色卡片、视频里的 Novel Core,其实都来自这类问答。
准确说,这些问题不是我坐在 NotebookLM 里一条条手动问的,而是 Hermes Agent 按 workflow 去问 NotebookLM,再把回答保存下来。
这也是这套流程跟“我打开网页问 AI”最大的区别:人负责设计问题链条和判断质量,Agent 负责把这些问题稳定地跑完、落盘、继续喂给后面的 Studio 生成步骤。
问答片段 1:拉斯柯尔尼科夫的理论到底是什么?
Hermes Agent 问 NotebookLM:
请只基于当前来源《罪与罚》,用中文回答: |
NotebookLM 的回答里,最有用的是它把这个问题拆成了三层:
核心主张: |
这段回答后来很适合改造成 PPT 的“犯罪理论与心理裂缝”页面。它不是一句“主角有犯罪理论”,而是已经天然分好了:理论、辩护、破产。
问答片段 2:心理崩塌不是一个瞬间
Hermes Agent 接着问:
请只基于当前来源《罪与罚》,用中文回答: |
NotebookLM 给出的回答是一条时间线:
阶段一:神经质的恐慌与理智的涣散。 |
这类回答对文章很重要,因为它把小说阅读从“人物很痛苦”推进到了“痛苦如何发生”。后面做视频分镜、PPT 时间线、读书会讨论时,素材就不再是散的。
问答片段 3:索尼娅不是简单的“善良女性”
Hermes Agent 继续问:
请只基于当前来源《罪与罚》,用中文回答: |
NotebookLM 的回答里,我最想保留的是这几段:
苦难: |
这就是为什么我在 PPT 和信息图里不想把索尼娅写成“善良女主”。她更像是整个 workflow 里必须被保留下来的复杂节点:苦难、信仰、陪伴、忏悔都压在她身上。
问答片段 4:哪些内容适合变成 Studio 产物?
最后,Hermes Agent 还问了一个更“workflow”的问题:
请只基于当前来源《罪与罚》和当前 notebook 的 workflow 目标,用中文整理: |
NotebookLM 的回答基本就变成了后续 Studio 产物的素材表:
适合画成图的人物关系: |
这一步非常关键。
因为它把“问答”变成了“生产计划”:哪些进 PPT,哪些进信息图,哪些进视频,哪些留给读书会。
这也是我说 NotebookLM 不只是问答工具的原因。问答如果被 workflow 接住,就会变成后续内容生产的结构。
Prompt 不是装饰,它决定了产物性格
这次我把 NotebookLM Studio 的 prompts 都留了下来。
它们在:
demos/zuiyufa/prompts/ |
比如 PPT prompt 不是一句“生成一个 PPT”,而是非常明确地写了目标:
请生成中文详细版 PPT,不是简洁概览。 |
它还限制了来源:
只使用当前 NotebookLM 来源中的《Crime and Punishment / 罪与罚》文本, |
甚至页数和密度也写清楚了:
18–24页。 |
这类 prompt 的作用不是“让 AI 更听话”这么简单。
它是在告诉 NotebookLM:这不是一份轻量摘要,而是一套可以拿去读书分享的材料。
视频 prompt 也一样。
它不是让 NotebookLM 随便讲一本书,而是要求按 7 个分镜组织:Hook、Source、Ready Gate、Novel Core、Artifact Matrix、QA、Delivery。
里面有一句我很喜欢:
一本厚小说不是只要“总结”,而是要变成可讲、可看、可交付的一组材料。 |
这几乎就是整个项目的核心。
最危险的状态不是失败,而是“看起来成功”


这次最典型的翻车,是信息图。
第一次信息图生成成功了。
文件能打开,状态也是 completed。乍一看,流程跑通了。
但打开图之后就发现不对。中文不稳,有错字,有挤压,有些地方像是模型努力写了中文,但没有写对。
这类问题特别讨厌。
因为它不是彻底失败。
彻底失败反而简单:命令报错,文件不存在,上传 timeout,处理路径很明确。
真正危险的是它“看起来成功”。
我又 retry 了一次。
第二次好了一点,但仍然不稳定。validation summary 里最后写得很直白:初版和第一次 retry 均未交付,原因是中文文字错误。
这时我没有继续赌模型。
如果只是不断重试,期待下一次运气好,那不是 workflow,是抽卡。
我最后改了策略:缩短文案,固定模块,降低自由生成空间。
最终版 prompt 变成了这种风格:
严格要求:只允许出现下面列出的文字。 |
然后只给很短的固定文案:
小说主线 |
这一次终于通过 QA。
这个翻车现场让我对 AI workflow 有了一个很明确的判断:
AI workflow 里最危险的状态不是失败,而是“看起来成功”。
所以 QA 不是最后可有可无的一步。
它是 workflow 的一部分。
PPT 要检查页数、结构和可读性。
视频要检查格式、时长、分辨率、音视频流。
信息图要检查中文、排版和截断。
Drive 交付前要确认文件完整、链接可用。
这不是洁癖。
这是为了避免把“看起来成功”的东西交出去。
一次真实跑通,会留下很多不好看的细节

我很喜欢 validation_summary.md 这个文件。
它没有什么传播性,也不适合发朋友圈,但它让这次实测变得可信。
里面记录了几个卡点:
zlib 普通下载要求 TTY,非交互环境失败;改用 skill 内 noninteractive_download.go。 |
这些细节不漂亮。
但真实项目就是这样。
如果一篇文章只展示最终 PPT、最终信息图、最终视频,看起来会顺很多。但我反而觉得,这些 timeout、路径问题、中文错字、重试记录,才说明这条 workflow 真的跑过。
工程化不是把失败藏起来。
工程化是让失败可以被发现、被记录、被修复、被写进下一次流程。
它适合谁,不适合谁

这套东西很适合读书博主。
读完一本书之后,最耗时的往往不是写一句感想,而是把它变成不同平台能用的材料:长文、PPT、信息图、视频脚本、读书会问题。
它也适合读书会组织者。
一本复杂的书,如果提前有人物关系、主题问题、关键冲突和讨论卡片,大家不容易只停留在“我觉得很好看”或者“我没看懂”。
老师、培训者、技术写作者、研究员、内容创作者,也都能用。
只要你的工作里有“把资料变成可讲、可展示、可复用材料”这件事,它就有价值。
但它不适合几类人。
如果你想完全不读书,只拿 AI 摘要当阅读结果,它不适合。
如果你不愿意复核产物,觉得生成了就能发,它也不适合。
如果你不关心版权和资料来源合规,只想把下载能力当卖点,那会把主题带偏。
如果你希望一次 prompt 就稳定产出高质量内容,也会失望。
这套 workflow 的价值不是魔法。
它只是把很多重复动作串起来,把很多失败处理沉淀下来,把很多生成结果放进质量闸门里。
听起来没有“一键读书”刺激,但更接近真实可用。
AI 不替我读书,它只是把书桌收拾好

跑完《罪与罚》之后,我对 NotebookLM 的看法有点变了。
它当然可以是一个文档问答工具。
但如果只把它当聊天框,就会错过很多东西。
更有意思的用法,是把它放进 Agent workflow 里:Hermes Agent 负责调度,Codex 帮我迭代 skills,CLI/Skills 负责跑腿和检查,NotebookLM 负责理解 source、回答问题和生成 Studio 产物。
最后得到的不是一段摘要。
而是一组读书配套材料:人物关系、章节结构、主题拆解、讨论问题、PPT、信息图、视频概览、音频概览,以及 Drive 目录、manifest、checksum、validation summary。
但我还是要自己读书。
我还是要判断哪些问题重要,哪些表达准确,哪些观点是我真正认同的。
AI 书童能做的是把资料整理好,把可能用得上的素材备好,把生成结果先检查一遍,把文件归档到该去的地方。
真正的判断和表达,还是我的事。
所以我不觉得它是在替我读书。
它更像是在我读书的时候,把书桌收拾好。
Comments